
En el mundo del Machine Learning, Random Forest se destaca como uno de los algoritmos más potentes y versátiles. Este método de aprendizaje supervisado se utiliza para clasificación y regresión, y es conocido por su capacidad para manejar grandes cantidades de datos y características complejas.
¿Qué es Random Forest?
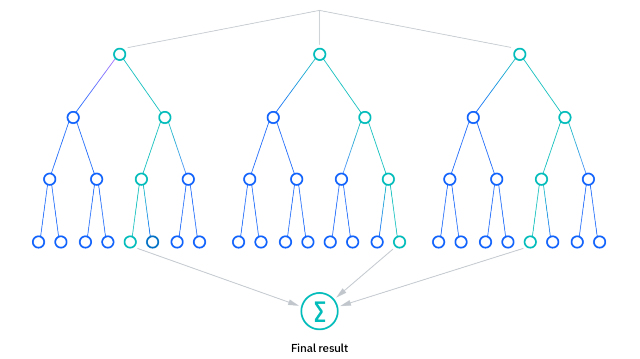
Random Forest es un algoritmo de ensamble que se basa en la creación de múltiples árboles de decisión. Cada árbol se entrena con una muestra aleatoria de los datos, y el resultado final se obtiene agregando las predicciones de todos los árboles. Esto permite que el modelo reduzca el riesgo de sobreajuste y mejore su precisión.
Desarrollado por Leo Breiman y Adele Cutler en la década de 2000, Random Forest ha evolucionado para convertirse en una herramienta fundamental en el análisis predictivo. Su popularidad se debe, en gran parte, a su capacidad para manejar tanto variables numéricas como categóricas, lo que lo hace aplicable en diversas industrias, desde la salud hasta las finanzas.
¿Cómo funciona Random Forest?
El funcionamiento de este método de Machine Learning se puede dividir en dos etapas: entrenamiento y predicción.
Fuente: https://www.ibm.com/topics/random-forest
1. Entrenamiento
Durante la fase de entrenamiento,el algoritmo utiliza el método de muestreo Bootstrap, que selecciona aleatoriamente una parte de los datos originales para construir cada árbol. Esto significa que algunos ejemplos de datos pueden ser elegidos más de una vez, mientras que otros pueden no ser seleccionados en absoluto.
Adicionalmente, al construir cada árbol, se selecciona un subconjunto aleatorio de características en cada nodo para decidir la mejor división. Este enfoque ayuda a aumentar la diversidad entre los árboles y, por lo tanto, mejora la robustez del modelo final.
2. Predicción
Una vez que se han construido múltiples árboles, cada uno emite una predicción. Para tareas de clasificación, la clase que recibe la mayoría de los votos se elige como la predicción final. Para tareas de regresión, se promedia el resultado de todos los árboles. Este proceso de votación o promediado permite que el algoritmo genere resultados más estables y precisos.
Relevancia de Random Forest
La relevancia de este método de aprendizaje radica en su capacidad para:
– Manejo de datos faltantes: Puede manejar valores perdidos sin necesidad de eliminar registros completos.
– Importancia de características: Ofrece métricas para determinar la relevancia de cada característica en el modelo, lo que ayuda en la selección de variables.
– Versatilidad: Se puede aplicar en diversas áreas, como diagnóstico médico, detección de fraudes y análisis de marketing.
– Resistencia: Su enfoque de ensamble reduce significativamente el riesgo de sobreajuste en comparación con un solo árbol de decisión.
Aplicaciones en el mundo real
El algoritmo se ha utilizado exitosamente en muchas aplicaciones. En la salud, por ejemplo, se ha empleado para predecir enfermedades y determinar tratamientos efectivos. En el ámbito financiero, ayuda a detectar fraudes y evaluar riesgos crediticios. Asimismo, en marketing, permite segmentar clientes y predecir comportamientos de compra.
Random Forest se ha consolidado como un algoritmo esencial en el ámbito del Machine Learning. Su capacidad para manejar grandes volúmenes de datos, su resistencia al sobreajuste y su versatilidad en diversas aplicaciones lo convierten en una herramienta invaluable para analistas y científicos de datos.
Si estás buscando implementar soluciones de Machine Learning en tu negocio, DataQu está aquí para ayudarte. Nuestro equipo de expertos puede diseñar y ejecutar proyectos de análisis de datos personalizados que impulsen tu éxito.
¡Contáctanos hoy y descubre cómo podemos transformar tus datos en decisiones estratégicas!

