
En la inteligencia artificial y el aprendizaje automático, los algoritmos como Random Forest y Gradient Boosting se han convertido en herramientas esenciales para resolver problemas complejos de predicción y clasificación. Si trabajas en una empresa que maneja grandes volúmenes de datos, seguramente te has topado con estos dos métodos. Pero, ¿cuál es el adecuado para tus necesidades? En este artículo, vamos a desglosar las diferencias clave entre ambos, y cómo cada uno puede beneficiar a tu negocio en función de tus objetivos.
¿Qué es Random Forest?
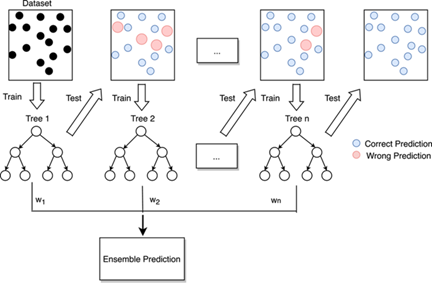
Es un algoritmo de aprendizaje supervisado que utiliza múltiples árboles de decisión para hacer predicciones más precisas. Se considera un algoritmo “ensamble”, es decir, combina varios modelos para producir una mejor predicción que la que podría ofrecer un solo árbol de decisión.

Fuente: https://www.ibm.com/topics/random-forest
¿Cómo funciona Random Forest?
El proceso de Random Forest implica la creación de múltiples árboles de decisión, cada uno entrenado con un subconjunto aleatorio de datos. A continuación, los resultados de cada árbol se combinan para llegar a una predicción final. Este enfoque reduce el riesgo de overfitting (sobreajuste) y mejora la generalización del modelo.
¿Qué es Gradient Boosting?
Es otro algoritmo de aprendizaje supervisado que también utiliza árboles de decisión, pero a diferencia de Random Forest, los árboles se entrenan de forma secuencial, corrigiendo los errores de los árboles anteriores. Esta técnica es conocida por su capacidad para mejorar de manera continua los modelos, lo que lleva a predicciones más precisas.
Fuente: https://www.researchgate.net/figure/Flow-diagram-of-gradient-boosting-machine-learning-method-The-ensemble-classifiers_fig1_351542039
¿Cómo funciona Gradient Boosting?
En Gradient Boosting, cada nuevo árbol se ajusta para corregir los errores cometidos por el árbol anterior. Este enfoque secuencial permite que el modelo aprenda de manera más precisa de los errores anteriores, lo que generalmente conduce a una mayor precisión en las predicciones.
Comparación de Random Forest y Gradient Boosting
| Característica | Random Forest | Gradient Boosting |
| Precisión | Moderada a alta | Alta |
| Velocidad de entrenamiento | Rápido | Más lento |
| Tendencia al overfitting | Baja | Alta |
| Facilidad de implementación | Alta | Media a baja |
| Manejo de datos | Excelente | Menos robusto ante datos ruidosos |
¿Cuál es el adecuado para tu empresa?
Random Forest es ideal si tienes muchos datos y quieres un modelo robusto, fácil de implementar y que ofrezca un buen rendimiento sin demasiado ajuste de parámetros.
Gradient Boosting, por otro lado, es perfecto si necesitas alta precisión y estás dispuesto a invertir más tiempo en ajustar el modelo. Es especialmente útil cuando se requiere optimizar detalles para obtener las mejores predicciones posibles.
Ambos algoritmos son herramientas poderosas, pero su efectividad depende del tipo de problema y los objetivos de tu empresa. En DataQu, entendemos la importancia de elegir las herramientas adecuadas para optimizar tus procesos de datos y mejorar la eficiencia de tu negocio.
Si tienes dudas sobre cuál de estos algoritmos se adapta mejor a tus necesidades, ¡contáctanos! Nuestro equipo de expertos está listo para ayudarte a tomar decisiones más informadas y llevar tu empresa al siguiente nivel.

